
背景
共识算法:在分布式系统中多个节点对某事达成一致
通过多副本的方式确保高可用,单副本损坏率x,则多副本可靠性理论值:n 副本 = 1 - x^n
复制算法
主从异步复制
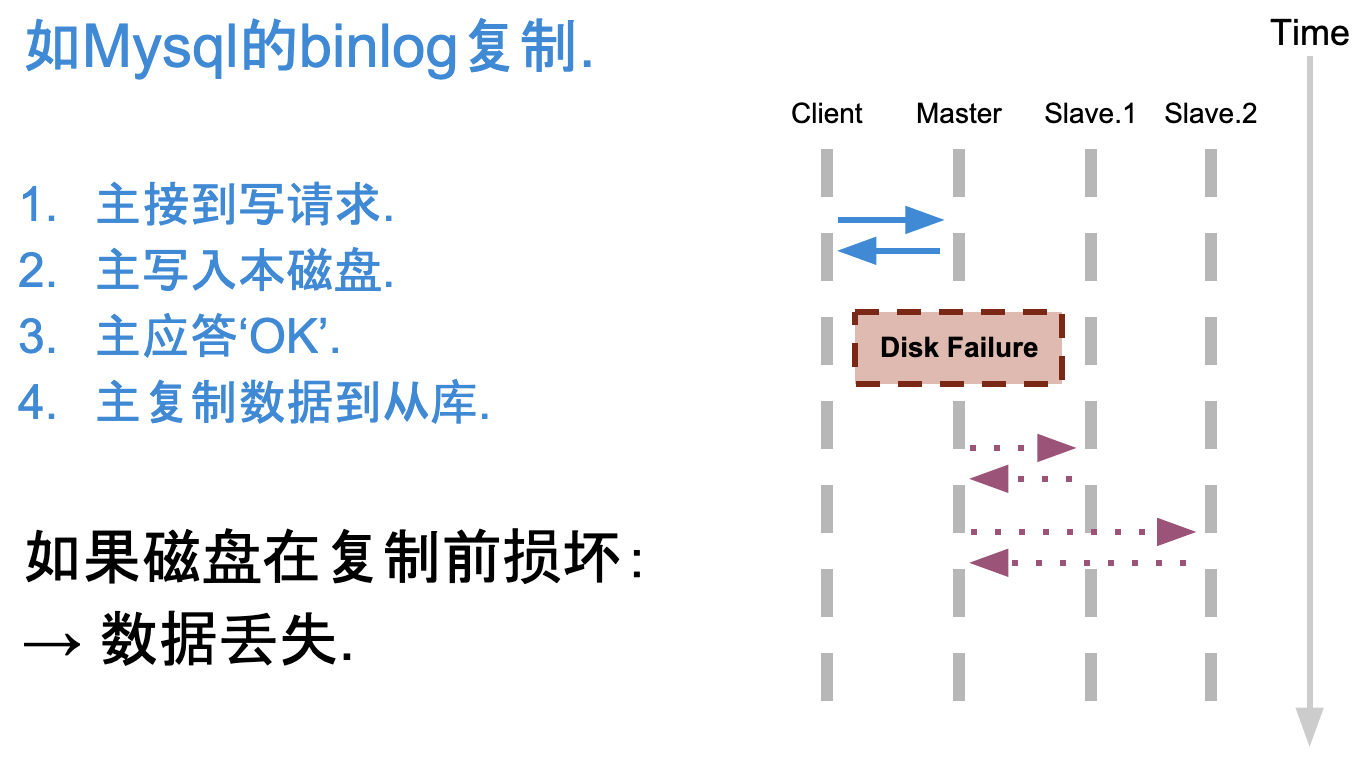
主从同步复制
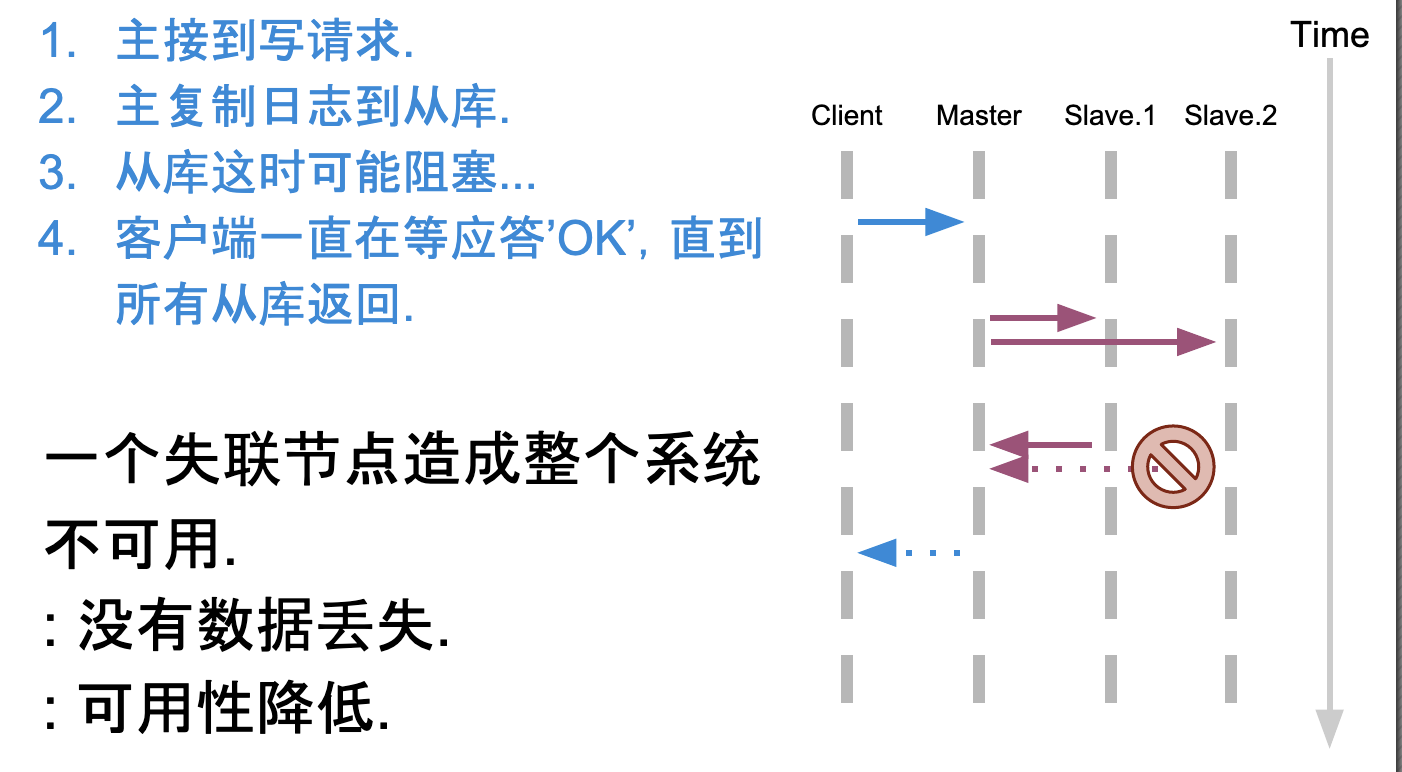
主从半同步复制
之前的认知里感觉主从半同步复制用的较多,需要注意其缺点是任何从库可能都不完整,那么从库在处理后续读请求时可能产生问题,因此诞生了多数派读/写
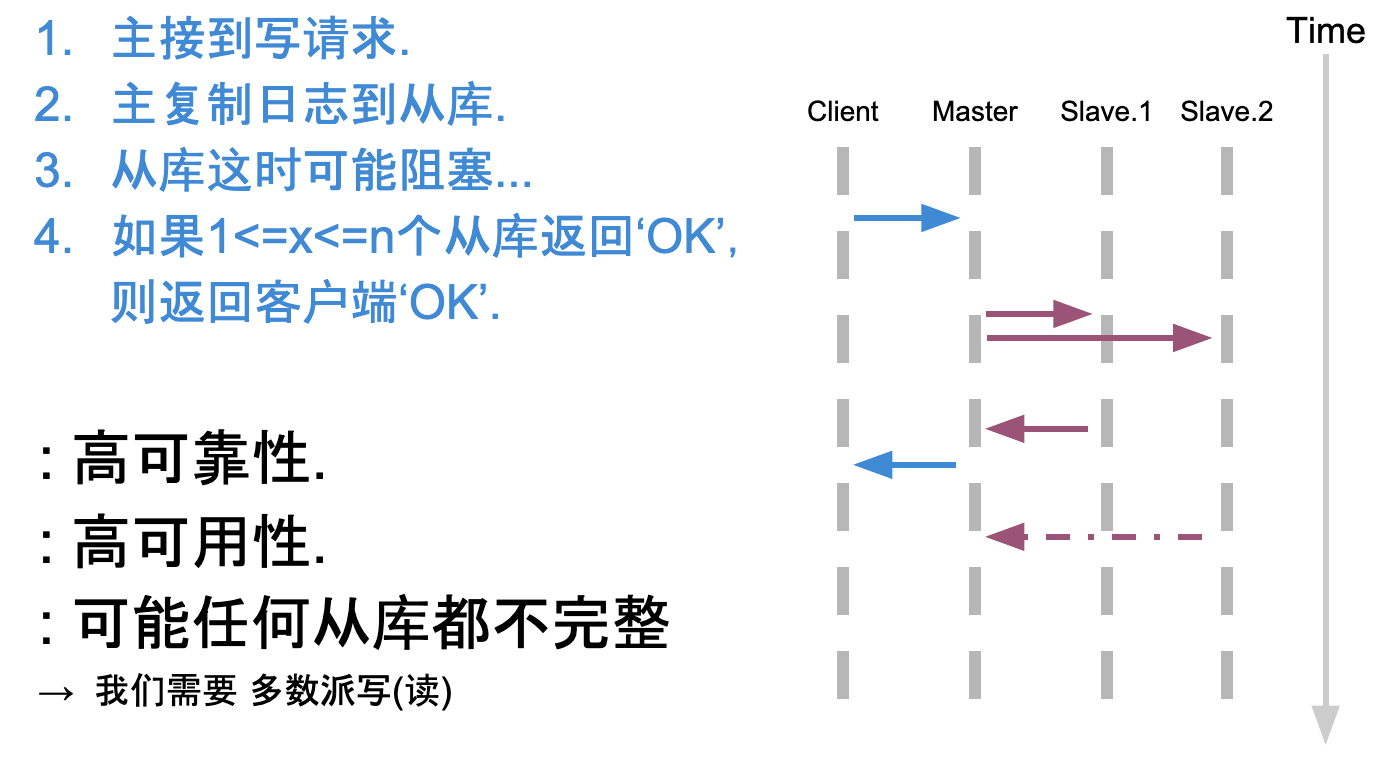
多数派写
多数派写,后写入优胜,最后1次写入覆盖先前写入,所有写入操作需要有1个全局顺序:时间戳
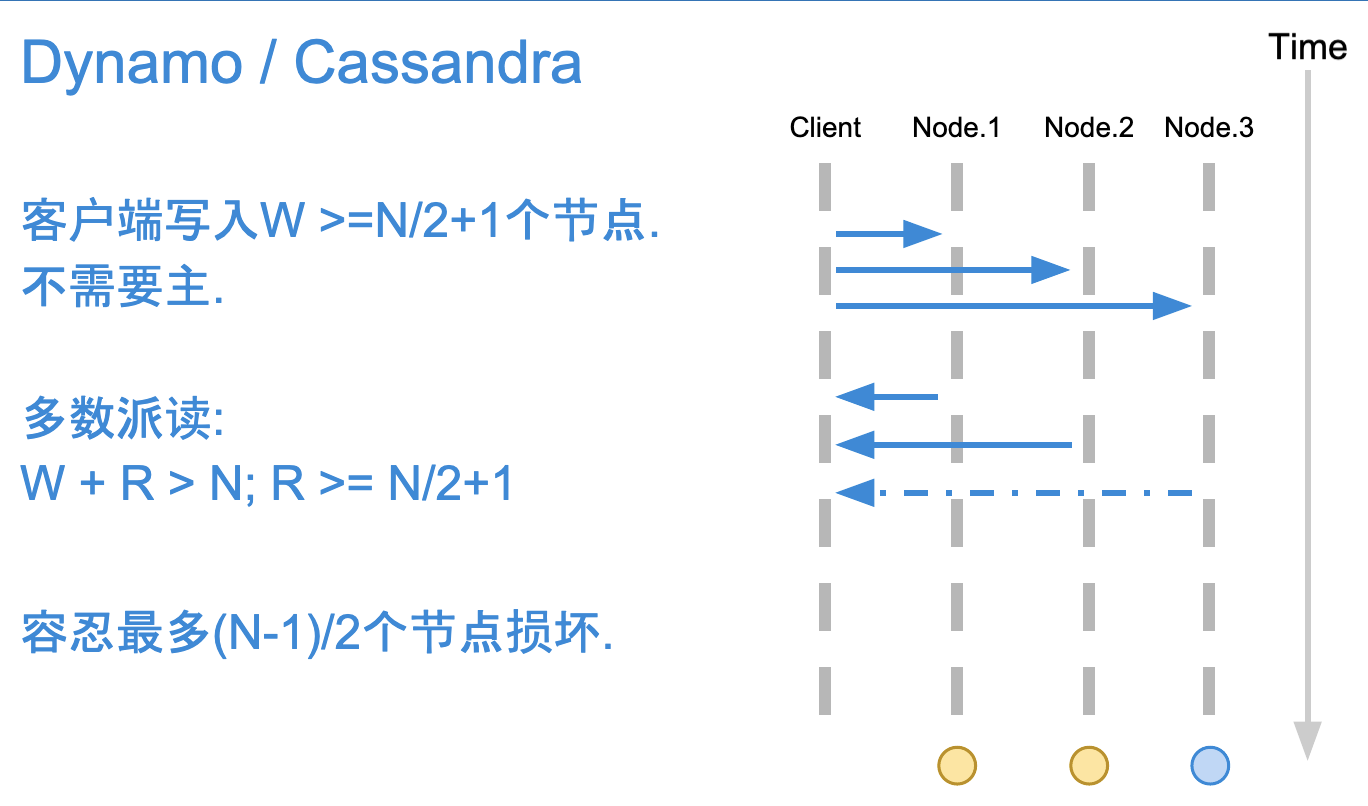
多数派读,即以大多数节点的val为最终读取的结果
优点:
- 数据的高可靠:没有数据丢失
- 高可用,最多允许挂(N-1)/2
- 数据完整性有保证
一致性:最终一致性
多数派读写缺陷
事务性:1. 非原子更新;2. 脏读;3. 更新丢失的问题
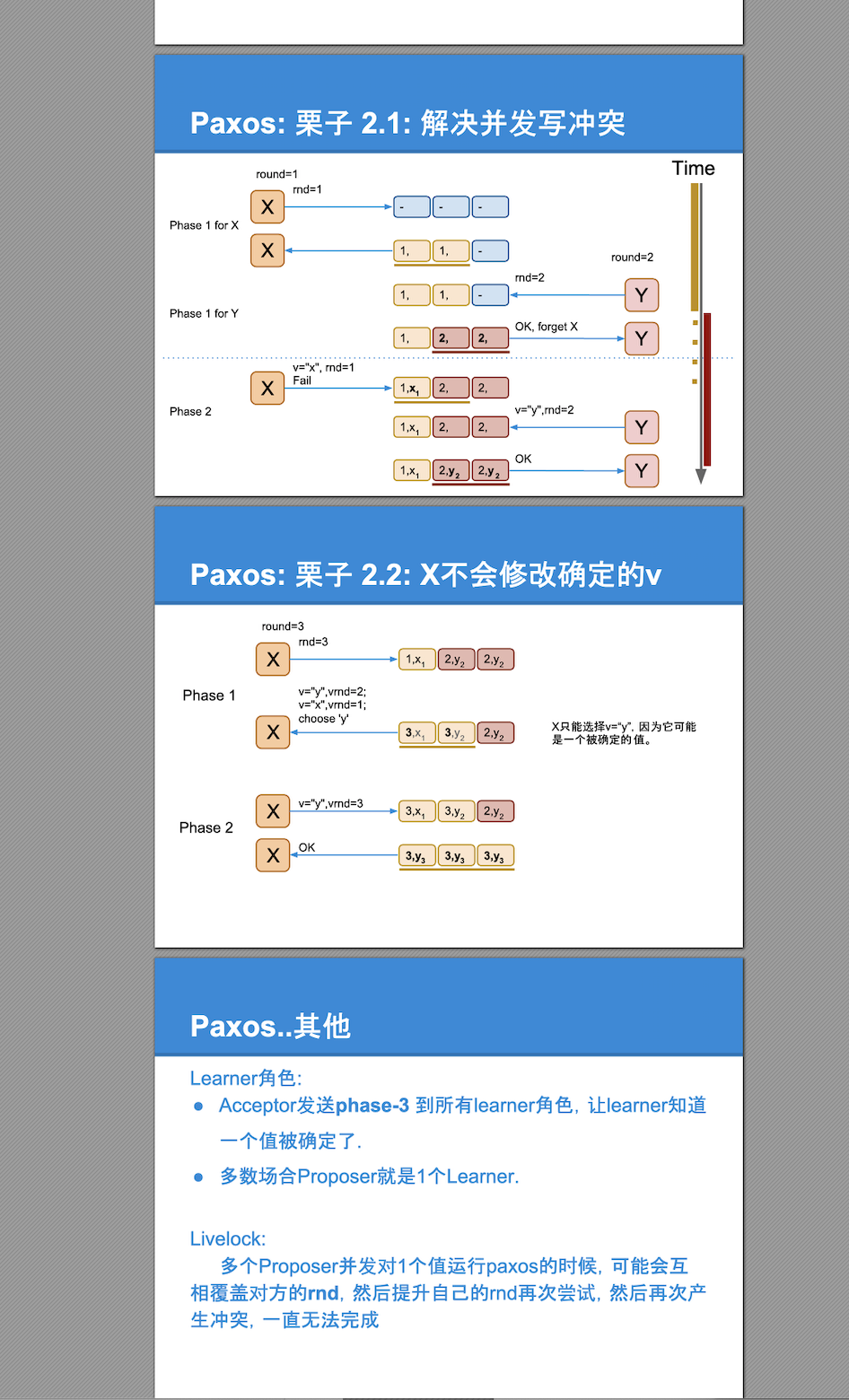
在上述演进下诞生了Paxos,这也解释了经典的Paxos为什么需要两个阶段,第一阶段确定写入的多数派节点(或者确定讨论的提案号),第二阶段确定提案的具体value
Paxos
- 一个可靠的存储系统: 基于多数派读写.
- 容忍消息丢失和乱序
- 每个paxos实例用来存储一个值.
- 用2轮RPC来确定一个值.
- 一个值‘确定’后不能被修改. ‘确定’指被多数派接受写入.
- 强一致性
- 前提:不解决拜占庭将军问题,即要求信道和存储是可靠的
分类
Classic Paxos
1个实例(确定1个值)写入需要2轮RPC.
Multi Paxos
约为1轮RPC,确定1个值(第1次RPC做了合并).
Fast Paxos
没冲突:1轮RPC确定一个值.
有冲突:2轮RPC确定一个值
角色
Proposer: 发起paxos的进程.
Acceptor: 存储节点,接受、处理和存储消息.
Quorum(Acceptor的多数派) : n/2+1个Acceptors.
Round:1轮包含2个阶段:Phase-1 & Phase-2
每1轮的编号 (rnd): 单调递增;后写胜出;全局唯一(用于区分Proposer);
Classic Paxos
流程
异常写入处理
Multi-Paxos
通过选择一个proposer作为leader降低多个proposer引起冲突的频率,合并阶段一从而将一次决议的平均消息代价缩小到最优的两次(将多个paxos实例的phase-1合并到1个RPC;使得这些paxos只需要运行phase-2即可),实际上就算有多个leader存在,算法还是安全的,只是退化为经典的paxos算法。
应用:chubby zookeeper megastore spanner
Fast-Paxos
● Proposer直接发送phase-2.
● Fast Paxos的rnd是0.0保证它一定小于任何一个Classic rnd ,所以可以在出现冲突时安全的回退到Classic Paxos.
● Acceptor只在v是空时才接受Fast phase-2请求
● 如果发成冲突,回退到Classic Paxos,开始用一个 rnd > 0来运行。
思考
讲解一个知识点最好的方式,其实是抽丝剥茧,一层一层深入。
为什么要多个acceptor?单个有什么问题。(单个无法保证高可用)
为什么进而演进到两阶段?(避免多数派读写在事务性方面的缺点,如并发写场景下的更新丢失问题)
为什么propose阶段还需要一个唯一递增ID,这个设计解决了什么问题。(1. 保证日志的安全性,即不能改变已经确定的值,2. 保序)
思想有了,paxos怎么应用到实际工程中?(一般都用优化后的multi-paxos,不同的实现会有些差异,如zk的zab)
这样才可能把一种知识的来龙去脉讲得透彻,而不是一上来就是 paxos 两阶段,先propose后accpet,算法倒是懂了但怎么用呢?这不是传道受业最佳的方法。
Raft
节点的三种state,同一时间只能是其中的一个角色
Leader(领导者):负责日志的同步管理,处理来自客户端的请求,与Follower保持heartBeat的联系;
Follower(追随者):刚启动时所有节点为Follower状态,响应Leader的日志同步请求,响应客户端请求,把请求到Follower的事务转发给Leader;
Candidate(候选者):负责选举投票,Follower节点与Leader之间的心跳超时则Follower转为Candidate发起选举,选举出Leader后从Candidate转为Leader(得到多数选票)或Follower;
Leader Election
two timeout settings which control elections
- election timeout:amount of time a follower waits until becoming a candidate, is randomized to be between 150ms and 300ms.
- election term: After the election timeout the follower becomes a candidate and starts a new election term(term + 1)
- 标识leader的合法性:实际上raft协议在leader选举阶段,由于老leader可能也还存活,也会存在不只一个leader的情形,只是不存在term一样的两个leader,因为选举算法要求leader得到同一个term的多数派的同意,同时赞同的成员会承诺不接受term更小的任何消息。这样可以根据term大小来区分谁是合法的leader(避免出现两个leader,非法的节点也能依据此感知到并更改自身的状态)
- 当某节点收到的请求中Term比当前Term小时则拒绝该请求
- 在一个Term期间每个节点只能投票一次
选举流程
- After the election timeout the follower becomes a candidate and starts a new election term(term + 1)
- vote fot itself and sends out Request Vote messages to other nodes.
- If the receiving node hasn’t voted yet in this term then it votes for the candidate …(先到先得,同时比较当前的日志是否比自己的新) and the node resets its election timeout.
- Once a candidate has a majority of votes it becomes leader.(多数派保证了在一个term中至多只有一个leader会被选举出来)
- The leader begins sending out Append Entries messages to its followers.(通过心跳的形式,开始发送同步日志)
- Followers then respond to each Append Entries message.
- 这个term会持续直到下一次follower接受心跳超时变为candidate
一个term中无leader诞生的场景
two nodes become candidates at the same time then a split vote can occur.
比如一共4个节点,2个节点同时变为candidates,发起投票,根据同一term中先到先得又各自获得一个选票,均达不到多数,导致该轮无leader诞生
The nodes will wait for a new election and try again.(因为各自的election timeout是随机值,只要下一轮不是同时开始则可顺利选举出leader)
Log Replication
Once we have a leader elected we need to replicate all changes to our system to all nodes.(通过心跳发送Append Entries)
当Leader选举出来后便开始负责客户端的请求,所有事务(更新操作)请求都必须先经过Leader处理,这些事务请求或说成命令也就是这里说的日志,我们都知道要保证节点的一致性就要保证每个节点都按顺序执行相同的操作序列,日志复制(Log Replication)就是为了保证执行相同的操作序列所做的工作
两阶段提交
- 第一阶段:当leader接收到客户端的日志(事务请求)后先把该日志追加到本地的Log中,然后通过heartbeat把该Entry同步给其他Follower,Follower接收到日志后记录日志然后向Leader发送ACK
- 第二阶段:leader得到多数followe对请求的响应后将该日志设置为已提交并追加到本地磁盘中,通知客户端同时在下个heartbeat中Leader将通知所有的Follower将该日志存储在自己的本地磁盘中。
网络分区处理
Raft can even stay consistent in the face of network partitions.
- 比如现在5个节点ABCDE,出现了网络分区,AB / CDE,这时候根据选举有可能会出现两个leader,比如原来的leader是B,CDE中根据多数派又能选举出一个leader C(term+1)
- 这时候客户端发起写入请求,两个master都收到了,那么B对应只有2个节点,无法满足多数写,所以不会进入commit,但另一边C满足多数写,成功commit
- 之后网络分区恢复,根据term的规则,由于C的term高,所以B收到心跳后把自己转变为follower,同时回滚自己未提交的log并同步leader的log,Our log is now consistent across our cluster.
这是复杂一点的情况出现2个master,如果原来的leader处在分区后的多数派一边,则分区后少数派这边就不会选举出新的leader,之后恢复后依然能重新同步原来leader的log,保持一致
Safety
在Raft协议中,所有的日志条目都只会从Leader节点往Follower节点写入,且Leader节点上的日志只会增加,绝对不会删除或者覆盖。
这意味着Leader节点必须包含所有已经提交的日志,即能被选举为Leader的节点一定需要包含所有的已经提交的日志。因为日志只会从Leader向Follower传输,所以如果被选举出的Leader缺少已经Commit的日志,那么这些已经提交的日志就会丢失,显然这是不符合要求的。
这就是Leader选举的限制:
选举安全性(Election Safety):每个Term只能选举出一个Leader
Leader完整性(Leader Completeness):能被选举成为Leader的节点,一定包含了所有已经提交的日志条目。
回看算法基础中的RequestVote RPC:
| 参数 | 解释 |
|---|---|
| term | Candidate的任期 |
| candidateId | Candidate的ID |
| lastLogIndex | Candidate最后一条日志的索引 |
| lastLogTerm | Candidate最后一条日志的任期 |
| 参数 | 解释 |
|---|---|
| term | 当前任期,用于Candidate更新自己的任期 |
| voteGranted | true表示给Candidate投票 |
请求中的lastLogIndex和lastLogTerm即用于保证Follower投票选出的Leader一定包含了已经被提交的所有日志条目。
- Candidate需要收到超过版本的节点的选票来成为Leader
- 已经提交的日志条目至少存在于超过半数的节点上
- 那么这两个集合一定存在交集(至少一个节点),且Follower只会投票给日志条目比自己的“新”的Candidate,那么被选出的节点的日志一定包含了交集中的节点已经Commit的日志
日志比较规则(即上面“新”的含义):Raft 通过比较两份日志中最后一条日志条目的索引值和任期号定义谁的日志比较新。如果两份日志最后的条目的任期号不同,那么任期号大的日志更加新。如果两份日志最后的条目任期号相同,那么日志比较长的那个就更加新。
ref:https://www.cnblogs.com/hzmark/p/raft_3.html
Raft paper翻译:https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md
Zab
zab是基于multi-paxos实现的,但感觉目前的实现版本和raft的思路更接近
- 选举:投票给日志最全的节点,也是通过任期+事务id进行判断,只不过zab的实现里把他俩用一个64位的zxid一起表示,高32位代表epoch(即任期term),低32位代表事务id,思路和raft一致
- 两阶段提交:同raft
- 日志恢复:有两个争议版本:
- 单向,leader有最全的数据,recovery的具体实现也只是leader到follower的单向同步。因为zab跟raft一样,都有顺序commit,日志连续的语义(zab里叫primary order)。
- 双向,zab的zookeeper实现中 ,一个prospective leader需要将自己的log更新为quorum里面最新的log,然后才好在synchronization阶段将quorum里的其他机器的log都同步到一致.
- 个人倾向于单向的方式,因为我理解zab的选主流程已经能同raft一样保证日志的连续性,可能是不同时期的zk实现方式不同导致的争议
区别与联系
区别
分治
问题较为复杂时可以把问题分解为几个小问题来处理,Raft也使用了分而治之的思想把算法流程分为三个子问题:选举(Leader election)、日志复制(Log replication)、安全性(Safety)三个子问题
leader地位
Raft协议比paxos的优点是容易理解,容易实现。它强化了leader的地位(Basic-Paxos没有leader的概念,在Multi-Paxos中进行了优化,通过选择一个proposer作为leader降低多个proposer引起冲突的频率),把整个协议可以清楚的分割成两个部分,通过选出一个leader来简化日志副本的管理,并利用日志的连续性做了一些简化:(1)Leader在时。由Leader向Follower同步日志 (2)Leader挂掉了,选一个新Leader,Leader选举算法。
日志
raft协议的Leader选举算法,新选举出的Leader已经拥有全部的可以被提交的日志,而multi-paxos择不需要保证这一点,这也意味multi-paxos需要额外的流程从其它节点获取已经被提交的日志。因此raft协议日志可以简单的只从leader流向follower在raft协议中,而multi-paxos则需要额外的流程补全已提交的日志。
Raft协议强调日志的连续性,multi-paxos则允许日志有空洞。日志的连续性蕴含了这样一条性质:如果两个不同节点上相同序号的日志,只要term相同,那么这两条日志必然相同,且这和这之前的日志必然也相同的,这使得leader想follower同步日志时,比对日志非常的快速和方便;同时Raft协议中日志的commit(提交)也是连续的,一条日志被提交,代表这条日志之前所有的日志都已被提交,一条日志可以被提交,代表之前所有的日志都可以被提交。日志的连续性使得Raft协议中,知道一个节点的日志情况非常简单,只需要获取它最后一条日志的序号和term。可以举个列子,A,B,C三台机器,C是Leader,term是3,A告诉C它们最后一个日志的序列号都是4,term都是3,那么C就知道A肯定有序列号为1,2,3,4的日志,而且和C中的序列号为1,2,3,4的日志一样,这是raft协议日志的连续性所强调的,好了那么Leader知道日志1,2,3,4已经被多数派(A,C)拥有了,可以提交了。同时,这也保证raft协议在leader选举的时候,一个多数派里必然存在一个节点拥有全部的已提交的日志,这是由于最后一条被commit的日志,至少被多数派记录,而由于日志的连续性,拥有最后一条commit的日志也就意味着拥有全部的commit日志,即至少有一个多数派拥有所有已commit的日志。并且只需要从一个多数集中选择最后出最后一条日志term最大且序号最大的节点作为leader,新leader必定是拥有全部已commit的日志
而对于multi-paxos来说,日志是有空洞的,每个日志需要单独被确认是否可以commit,也可以单独commit。因此当新leader产生后,它只好重新对每个未提交的日志进行确认,已确定它们是否可以被commit,甚至于新leader可能缺失可以被提交的日志,需要通过Paxos阶段一向其它节点学习到缺失的可以被提交的日志,当然这都可以通过向一个多数派询问完成
小结一下就是
选主方式:raft比较last_log_index以及last_log_term保证选出的leader已经拥有最完整的数据,zab(multi-paxos)仅通过节点标识选主,所以需要之后的recovery过程,不过实现中zab也采用了类似于raft的选主方式
恢复方向:raft单向,仅从leader到follower补齐log;multi-paxos双向,leader需要从follower接收数据来生成initial history
本质上,两者是一样的。一个日志被多数派拥有,那么它就可以被提交,但是Leader需要通过某种方式得知这一点,同时为了已经被提交的日志不被新leader覆写,新leader需要拥有所有已经被提交的日志之后才能正常工作,并且需要重新提交所有未commit的日志。两者的区别在于Leader确认提交和获取所有可以被提交日志的方式上,而方式上的区别又是由于是日志是否连续造成的,Raft协议利用日志连续性,简化了这个过程。
联系
- Raft和Paxos一样只要保证n/2+1节点正常就能够提供服务;
- 经典的paxos,从一个提案被提出到被接受分为两个阶段,第一个阶段去询问值,第二阶段根据询问的结果提出值。这两个阶段是无法分割的,两个阶段的每个细节都是精心设计的,相互关联,共同保障了协议的一致性。而VR,ZAB,Raft这些强调合法leader的唯一性协议,它们直接从leader的角度描述协议的流程,也从leader的角度出发论证正确性。但是实际上它们使用了和Paxos完全一样的原理来保证协议的安全性,当同时存在多个节点同时尝试成为leader或者不知一个节点认为自己时leader时,本质上它们和经典Paxos中多个proposer并存的情形没什么不同。
- 安全性保障都是利用了同一个性质:两个多数派集合之间存在一个公共成员。