
阿里今年新增加了所有人都要完成的笔试,我参加的是3.25下午的场次,结果做的不是很好,痛定思痛,确实暴露了一些问题,之后的反思如下:
心路历程
首先回顾一下两道题目与做题时的心路历程:
第一题
截图来源:https://www.nowcoder.com/discuss/391503?type=0&order=0&pos=10&page=1

最开始拿到这道题其实我脑海里有好多种思路:
- 一是把它转换成图论中的最短路径的问题求解,相当于每一列都要选择一个节点,构成通路,路之间的边权就是对应的绝对值;
- 二是贪心、dp好像也都能做
这样大概思考了5分钟,决定用贪心解(也反思了为什么会优先选择用贪心做,见下文)🤦♂️。。。
笔试完后一位大佬前辈和我说,一般能用dp解的如果用贪心都是错的,确实如此
于是乎我当时笔试时写的代码如下:
def helper(matrix): |
当时的贪心策略是每次选择与上一次abs距离最小的点作为下一次的点,其实贪心无法保证每次都得到最优解,一是这个问题无法通过反证法证明它具有贪心选择性质,二来很容易就能举出反例,如如5 6 2 2 2 2 2,那此时第二列就不会选到和5最接近的,而会选和2最接近的,所以正解应该用dp,可以保证每次都是全局最优解
所谓贪心选择性质是指所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到。这是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别。
当时用贪心写完代码再调试完过了测试case大概已经过去了20+分钟,第一次提交发现只过了5%,又提交了一次发现到10%了,于是开始怀疑是不是时间复杂度上刚好卡在一些case 的边缘,于是开始优化代码(当时并没有意识到是贪心不一定得到全局的最优解)。。。。又折腾了一会儿时间复杂度已经是o(3n)了,还是10%,决定放弃。此时时间已经过去了40分钟了。。。导致在后面第二题并不难的只是代码量较大的情况下,没能写完😵
结束之后看见讨论说第一题应该用dp,于是自己又去推dp的式子。。。不到3分钟就推出来了,然后很顺利地写完了代码,前前后后不超过20分钟,如下:
# dp[i][j]表示以第i行第j列为最后个数字的最小邻差 |
viterbi 算法
这道题确实可以用最短路的思想求解,具体的求法就是用viterbi 算法。
维特比算法 (Viterbi algorithm) 是机器学习中应用非常广泛的动态规划算法,在求解隐马尔科夫、条件随机场的预测以及seq2seq模型概率计算等问题中均用到了该算法。实际上,维特比算法不仅是很多自然语言处理的解码算法,也是现代数字通信中使用最频繁的算法。
好吧,因为不是NLP方向,所以对这块不熟。维特比算法其实就是上面的dp思想,我想NLP方向的小伙伴刷到这道题应该都笑出声了吧,一模一样
具体的算法细节可以查看如何通俗地讲解 viterbi 算法?
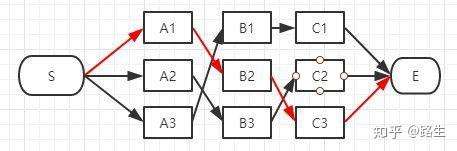
这里就放一个非常清晰地转化为最短路去做的示意图吧,连行数都能对上😰只不过在隐马的场景下求解的是最大的概率,而在这道题求解的是最小的和,max和min的区别吧(隐马简单来说就是通过已知的可以观察到的序列,和一些已知的状态转换之间的概率情况,通过综合状态之间的转移概率和前一个状态的情况计算出概率最大的状态转换路径,从而推断出隐含状态的序列的情况。)
第二题
没写完的第二题思路相对固定,一看就是老老实实模拟。
题目描述:
给定一个矩阵n*m,每行每列都是等差数列,但是有部分值是被隐藏了的,数值为0即是被隐藏了。
根据输入的值i,j,判断这个位置上的值是否可以被推导出来,可以就输出,否则输出Unknown
输入描述:
第一行三个整数,代表n、m、q
接下来n行,代表二维数组矩阵A[n*m]
接下来q行,每行两个整数i,j,访问矩阵中的可能值A[i][j]
输出描述:
输出q行
若能推导出来对应位置的矩阵元素值,返回该值
若无法推导出来,返回Unknown
示例输入:
2 3 6
1 0 3
0 0 0
1 1
1 2
1 3
2 1
2 2
2 3
1
2
3
4
5
6
7
8
9
10
示例输出:
1
2
3
Unkown
Unkown
Unkown
结束后又花了十分钟左右才写完,如下:
|
后来看了讨论说只用扫描三次即可填充完整个等差矩阵,行列行/列行列都可以。见:https://blog.csdn.net/qq_27003337/article/details/105100534
再看了看我自己写的,复杂度其实是一样的,只不过每次我都会判断下一次是否产生能够更新的行/列,没有的话结束循环,算了下这道题从开始写到最后写完过测试的case共花时40分钟左右,确实代码量比较大
网上很多通过90%case 的,问题应该在于原本矩阵中的0,有时候它就真的是0,所以在一开始我直接用大于数据范围的值去填充,这样就不会出现误判了
这题委实没啥难的,模拟就完事了,好可惜,没能写完
早知道先写第二题了Orz,这样过个90%也还过得去
一些感悟
回顾完了心路历程,有一些感悟:
当得知第一题用dp可以解的时候,3分钟就推出了递推式,但笔试时不确定用哪种方法时,就没想到了。这个很有意思,换句话说这道题如果出现在面试的场景就一定能写出来,因为面试时你会和面试官交流你的思路,面试官会及时纠正错误的思路,所以你下笔的时候思路一定是正确的。说到底还是刷的题不够多吧,现在虽然可以独立解决dp类中上难度的问题,但是对这个问题究竟采用何种方法的选择上还需多加训练
当时也反思了为什么笔试的时候想到过用dp,最后却没用呢,可能有点先入为主的思想,之前阿里的两场笔试我也做了,难度中上吧,大体的方向如下:
- 第一场的第一题dfs模拟,第二题sort之后直接LCS的dp;
- 第二场第一题找规律推公式加快速幂,第二题多加了个状态的bfs
然后有个前辈给所有的题目大概分了个类,他原话这样写的:
阿里笔试考的太宽泛了,你可以先把基础的模板题都做做。从基础算法,如二分,前缀和,排序;到基础数据结构,单调栈,单调队列,字符串哈希,trie,树状数组;再到贪心动规,贪心的可以刷点区间覆盖题,动规的太多了,背包dp,状压dp,区间dp等等;然后是搜索题,bfs刷点迷宮题,dfs刷树遍历的,然后就是图论的,最短路,二分图,强联通都做做,剩下就是数学题了,快速幂,逆元,筛素数
于是乎第三场我在做之前就觉得有比较大的概率会考察贪心,毕竟dfs,bfs,dp,快速幂都考过了。。。。。这也导致了在第一题没有考虑的非常全面的情况下直接上手撸了贪心的算法,先入为主的思想太危险了,以后需要避免,这样的心理暗示容易出问题。
时间管理,没有控制好每道题的时间分配,导致最后只有20分钟,然后第二题乍一看比较长的时候就有点慌了,整个心理状态就不一样,越急越容易出bug,bug越多写得越慢,如此恶性循环。当题目数量少的时候和多的时候又是不同的管理策略,以后需要严格设定每道题的止损时间,这次如果在30min时开始做第二题,或许就能顺利写完了。
写在最后
感慨一下阿里的笔试风格确实很独特,题目都是好题,值得推敲,不过这种1小时2道middle+难度的题对大家要求非常高,如果按面试的编程准备多半是做不出的。而且没有简单的题帮助你快速进入状态了,而做笔试其实挺吃状态的。
回忆了下之前保研也好,找实习也好,打的leetcode周赛也好,经历过的大大小小的笔试,这次是做的最差的,哎,痛定思痛,这下真是给后面的面试带来了很大的压力啊🤯本来面蚂蚁就是个比较激进的策略,现在难度又更上一层楼了,服了自己。。。。
现在回过头来看看,那天真的特别的忙,下午阿里笔试,晚上鹅厂微信的复试,真的是累炸,白天准备笔试,笔试完之后的两三个小时再准备准备面试,其实做完笔试心态已经有点崩了,幸好迅速调整了过来,投入到了晚上的面试,有惊无险,面完系统的状态就更新了,下一轮说是终面的面委会,听起来很厉害的样子,想起去年自己面pcg 的时候两轮技术就offer了,没有经历过这个状态,有点激动又有点紧张,不愧是wxg,不知道和阿里的交叉面是不是类似的。
各种意义上来讲下周都非常的关键,或许是备战春招的最后一周了,调整好状态,再复习一轮,在笔试失利的巨大劣势下,反败为胜,打好最后的仗💪
稳住, 我们能赢
最后贴上某(~ ̄(OO) ̄)ブ给我画的锦鲤2.0

后续
最后还是幸运地成功顶住了压力,都拿到了offer,具体见「20春招总结」啦~🎏